My previous blog post described donating home lab compute resources to cornavirus researchers. Will my home lab get bogged down and become painfully unresponsive? This is the first question I had after donating compute resources. Interest in doing good could quickly wane if it becomes difficult to get my work done.

The rapid growth of Folding@home resulted in temporary shortages of work units for computers enlisted in the project. A Folding@home work unit is a unit of protein data which requires analysis by a computer.
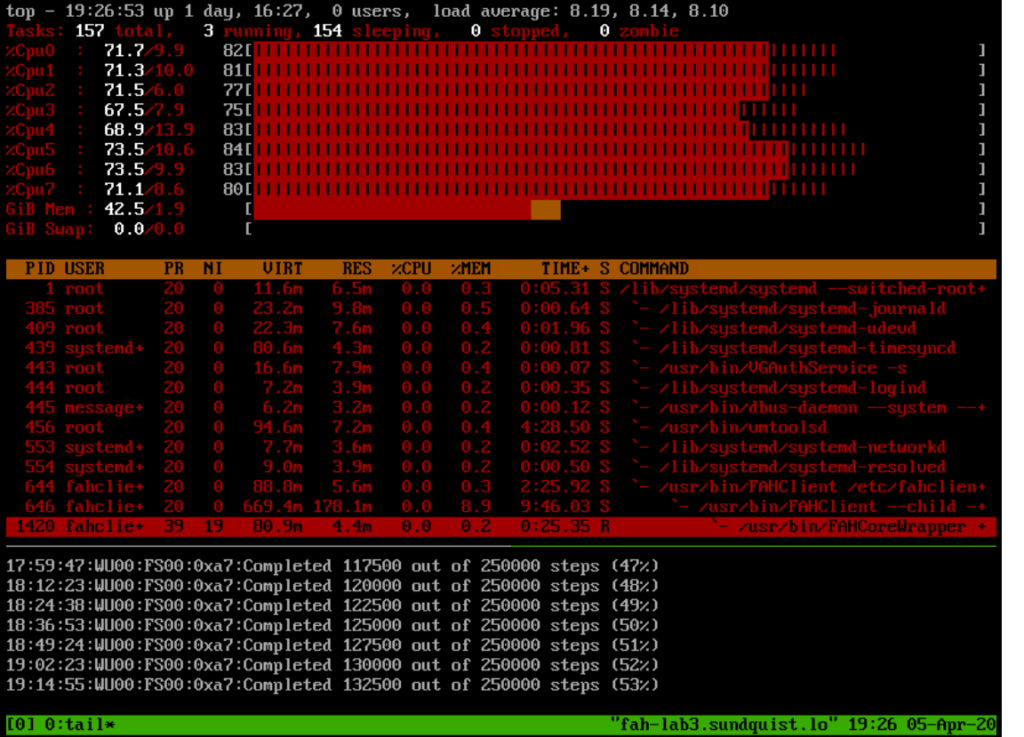
While waiting, I “discovered” Rosetta@home
The University of Washington (UW) Institute of Protein Design has a similar project called Rosetta@home. Even though I’m a different UW alumni (University of Wisconsin – not Washington) I’ve made Seattle my home over the last 12 years. I joined this project to help my neighboring researchers. It’s not as easy as deploying the VMware virtual appliance fling for Folding@home. First I manually created the vm, deployed Red Hat Enterprise Linux in each vm, updated the OS, and then installed the BOINC package. The BOINC package is available for many other OS’s.
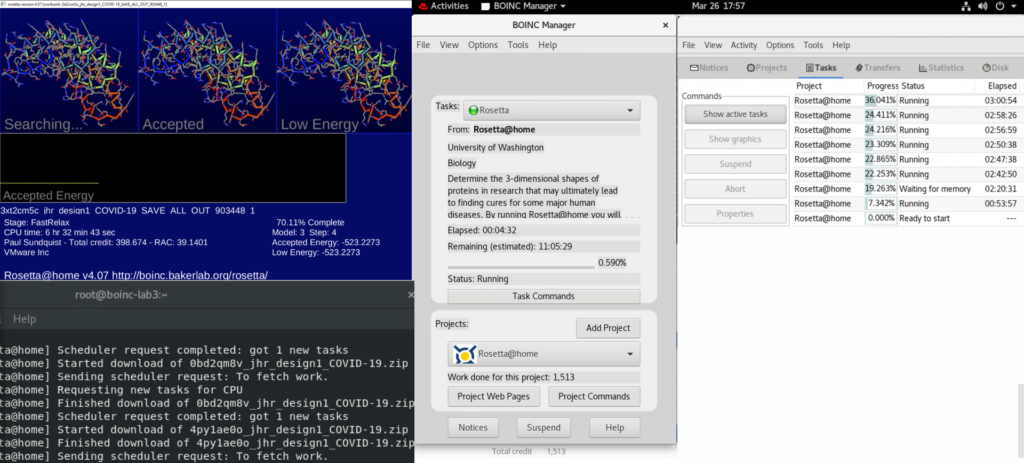
What if
What if I could prioritize my regular home lab work AND use excess capacity for Rosetta@home while I was waiting for the release of new Folding@home workloads? Could I retain my fast and responsive home lab and donate excess resources?
CPU’s are always executing instructions regardless if they have any work to do. Most of the time they have nothing to do. Instead of filling empty space with the idle process, Folding & Rosetta @home can execute instead of the CPU consuming empty calories.
Scheduling
vSphere’s Distributed Resource Scheduler (DRS) ensures that vms receives the right amount of resources based on the policy defined by the administrator. I reopened my course manual from the VMware Education “vSphere: Install, Configure, Manage plus Optimize and Scale Fast Track [V6.5]” class & exam I completed in 2018 to refresh my memory on the scheduling options available.
Resource Pools & Shares
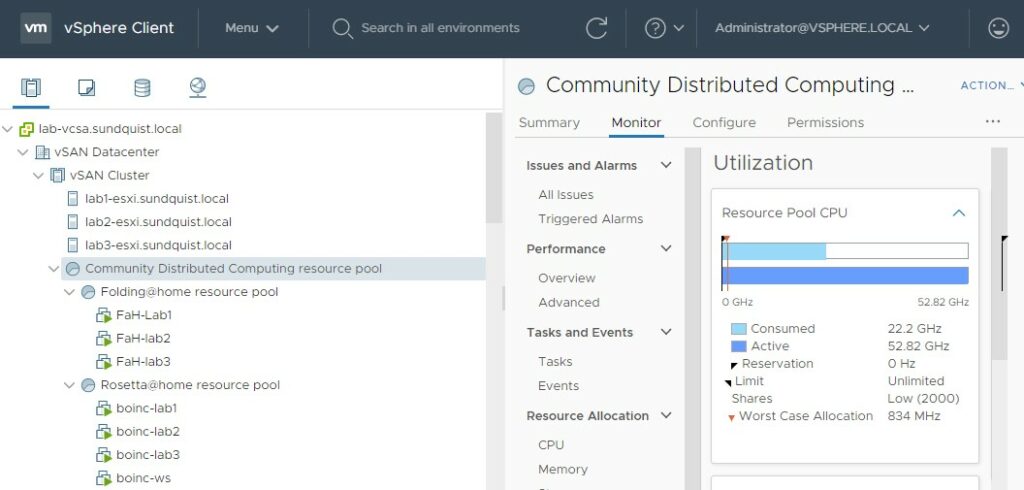
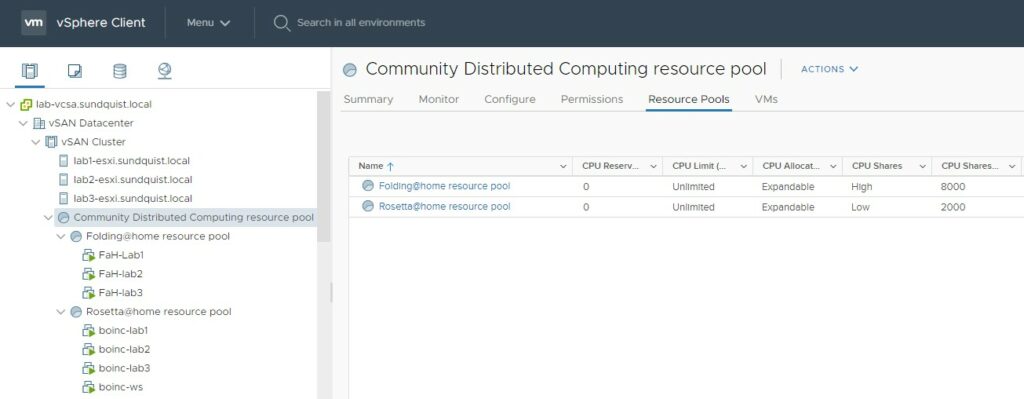
The above screenshot shows the DRS resource pools defined to achieve my CPU scheduling goals. This example uses vSphere 7 which was released last week however this feature has been available for many years. I utilized shares to maximize my CPU utilization by ensuring that the 24 CPU cores in my home lab are always busy with work instead of executing an idle process which does nothing.
I defined a higher relative priorities for regular workloads and a lower priority for “Community Distributing Computing” workloads. The picture below illustrates how the “Community Distributed Computing Resource Pool” is configured with low shares.
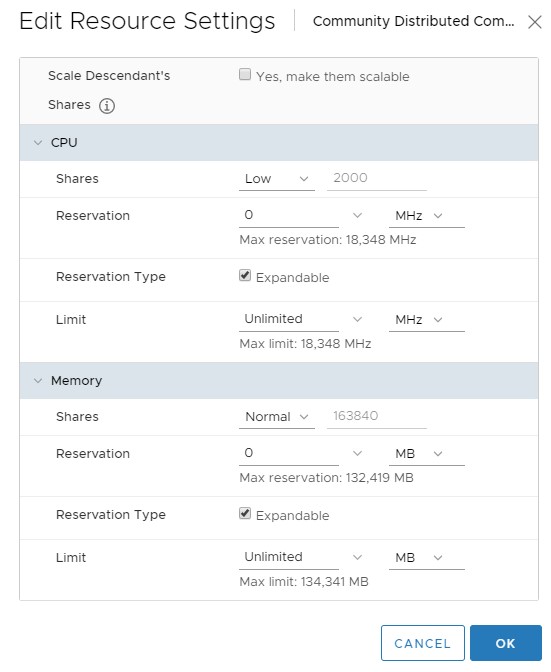
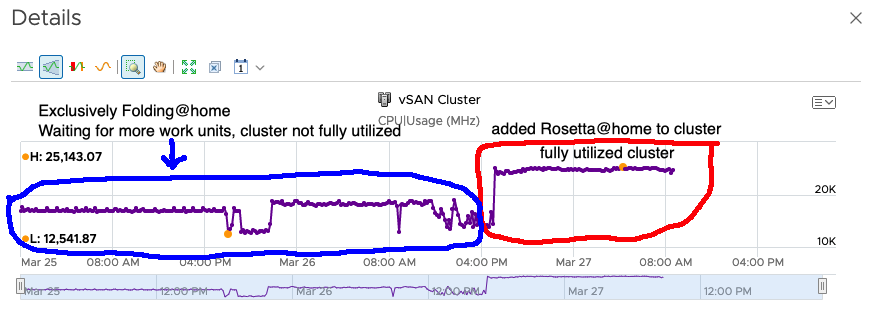
My individual regular workload vms by default have normal shares, which is a higher relative priority than the low shares resource pool shown above. This results in a negligible impact to performance for my regular workloads. I haven’t noticed the extra load which is fully utilizing the last drops of processing capacity my CPU’s. Below is a cluster based CPU usage utilization graph from vRealize Operations 8.0. The 3 CPU’s had plenty of unused capacity while they were waiting for Folding@home work units. This is circled in blue prior to adding Rosetta@home to the cluster. Once I added Rosetta@home with the DRS shares policy all of the CPU cores in the cluster were fully utilized, this is the area circled in red.
Prioritize Multiple Community Distributing Projects
I also utilized shares to prioritize the remaining CPU resources between Folding@home and Rosetta@home. Shown below is a high relative priority shares resource pool for Folding@home and a low relative priority shares resource pool for Rosetta@home. This example starves Rosetta@home for CPU resources when Folding@home is active with work units. If Folding@home is waiting for resources, Rosetta@home will claim all of the unused CPU resources. These relative priorities aren’t impacting my regular workloads.
Enterprise IT & Public Cloud Functionality
Large enterprise IT customers use these same features to fully utilize their data center resources. A common example is to place production and dev/test workloads on the same cluster, and provide production workloads a higher priority. Enterprise customers improve their data center return on investment since they don’t have underutilized computing resources. Public cloud providers use this same model to sell efficient compute services.
Happy Home Lab
The home lab is happy since it is contributing unused CPU processing power to the community without impacting performance of everything else. My next blog post will describe the sustainability of the solution and impact to my Puget Sound Energy electricity bill.
